


More’s coming, Huang said, describing the growing power of AI to reason and perceive. That leads us to agentic AI — AI able to understand, think and act. Beyond that is physical AI — AI that understands the world. The phase after that, he said, is general robotics.
The Nvidia story is the ring invention of the computer industry, started out as a chip company with a goal of creating a new computer platform. In 2006, Nvidia introduce Kuda, how it revolutionize how computer is done. In 2016, 10 years later, a new computing approached has arrived, it require a reinvention of every single layer of the technology stacks.
The processor, software & Systems are all new. So NVIDIA invented a new systems called NVIDIA GTX 1, but nobody understand & interested. So Jensen donated to a non profit company called OpenAI. And it started the AI revolution.
It is unlike traditional way, of running software on a few processors in a large data centre we called the hyperscale. This new type of apps, require many processes working together. Serving queries for million of people. And that data centre would be designed fundamentally different.
Nvidia realize there are 2 types of networks. One for north-south because you still have to control the storage, and connect to the outside. But the most important network was going to be east west, where the computer talking to each others to solve problem. Nvidia recognized the best networking company in east west traffic for HPC, large scale distributed process called Mellanox for $6.9 Billion in 2019 and converted an entire datacentre, into one computing unit. Thus, the modern computer is an entire datacentre. The datacentre is a unit of computing, no longer just a PC or a Server. The entire data centre running one jobs, Generative AI query. Nvidia data center journey is now very well known.However Jensen realize that NViDIA is infact in the centre of AI infrastructure company.

This infrastructure is not alike the first industrial revolution, where company like GE, Westinghouse, Siemens realized that there was a new type of technology called electricity. And new infrastructure
had to be build all around the world and become essential, part of social infrastructure called electricity
Years later during our generation, we realize there is a new type of infrastructure, that was very conceptual & hard to understand. And this infrastructure is called Information infrastructure, which make no sense to many people at that time.
But now we realize this information infrastructure is the Internet, that is everywhere, ubiquitous and everything is connected to it.
There is a new infrastructure now, and this new infrastructure was built on top of the first two, electricity and the information infrastructure or the Internet. This new type of infrastructure is infrastructure of Intelligent or AI and the world realize that AI has now integrated to everything and is everywhere, ubiquitous in every region, industry, country and every company, they all need AI. AI is now the infrastructure & the revolution, just like the internet or electricity needs factory. And these factory is what NVIDIA is going to focus and built today, an AI Factory or AI Data Centre.
This new AI Factory, is not traditional data centre of the past, but a $1 Trillion industry, not only providing information and storage like the traditional data centre. It is AI Data Centre (DC), which is in fact AI factory. You apply energy to this AI DC and it produce entirely different output Intelligent called Token
Now company talk about token and how many they produce last quarter or last month or
hour just like every factory does. So the world has fundamentally change by this AI Revolution and AI Data Centre.
All of this, factory has created demand for much more computing power. To meet those needs, Huang detailed the latest NVIDIA innovations from Grace Blackwell NVL72 systems to advanced networking technology, and detailed huge new AI installations from CoreWeave, Oracle, Microsoft, xAI and others across the globe.
“These are gigantic factory investments, and the reason why people invest in factory,” Huang said with a grin. “The more you buy, the more you make.”
GRACE BLACKWELL ULTRA SUPER CHIP – The Thinking Machine
Grace Blackwell has the ability to Scale Up, means to turn what is a computer into a giant super computer. Scale out is easier by taking many computer and to connect them together, but Scaling up is incredibly hard. Building larger computers with more powerful computing, that is beyond the limit of semiconductor physics is insanely hard. And that’s what Grace Blackwell does and broke just about everything about chips. And many of you in Taiwan including TSCMC, Foxconn, Gigabyte, MediaTek design and help NVIDIA build this AI Infrastructure, including Grace Blackwell systems. Jensen was so happy to say that NVIDIA is in full production, although it was incredibly challenging. Although the Blackwell systems based on HGX has been in full productions since the end of last year (2024) and has been available since this February 2025. We are now just putting online all the great Grace Blackwell NVL 72 “ A Thinking Machine”.
They’re coming online all over the place every single day. It’s available in core weave now for several weeks. Its already been used by many CSPs (Clouds Service Provider) and now you re starting to see it coming up every where. Everybody started to tweet out that Grace Blackwell is in full production.
In Q3 of this year, just as I promised, every single year, we will increase the performance of our platform every single year like Rhythm. And this year, in Q3 we’ll upgrade to Grace Blackwell GB300
The GB300 will increase using the same architecture. Same physical footprint, same electrical, mechanical but the chips inside have been upgraded & scale up. It has upgraded with a new Blackwell chip is now 1.5 x more inference performance. Has 1.5 x more HBM (High Bandwidth Memory) for GPU & Supercomputer and it has 2x more networking. And so the overall systems performance is higher
Grace Blackwell start with this compute node, what the last generation looks like the B200. This B300 must have 100% liquid cooling now and you could plug in into the same systems.
B300 has 1.5x more inference performance than B200. The training performance is about the same. This particular Blackwell B300 is 40 petaflops, which is approximately the performance of Sierra Supercomputer in 2018. The Siera super computer has 18,000 Voltage GPUs
This one node here replace that entire giant supercomputer.
4000 times increase in performance in 6 years. That is extreme Moore’s law. Remember I have said before that AI, NVIDIA has been scaling computing by about a million times every 10 years and we still on that track.
But the way to do that is not just to make the chip faste. There is only a limit to how fast you can make chips and how big you make chip.
Benchmarking Performance Grace Blackwell – dengan Supercomputer Siera (2018):
IBM Sierra Supercomputer (2018) Performa puncak 125 petaFLOPS (Quadrillion floating-point operations per second). Sebagian besar performa 120.9 petaFLOPS dengan NVIDIA Tesla V100 GPU. Arsitektur: Gabungan CPU IBM Power9 & GPU NVIDIA Tesla V100. Tujuan: User Sierra Lawrence Livermore National Laboratory untuk simulasi senjata nuklir & pekerjaan rahasia.
NVIDIA Blackwell DGX B300/GB300: Performa (Inference): Sistem DGX B300 oleh Blackwell Ultra GPUs capai 144 petaFLOPS inferensi FP4 (floating-point 4-bit) & 72 petaFLOPS Training FP8. Performa (Training): Blackwell Ultra B300 GPU capai 15 PFLOPS dense FP4.
Sistem DGX GB300 NVL72 gunakan 72 Blackwell Ultra GPUs & 36 Grace CPUs) capai 1.1 ExaFLOPS FP4 untuk inferensi d 360 petaFLOPS FP8 untuk training
Jadi perbandingannya antara Supercomputer IBM Siera(2018) dengan NVIDIA GB300:
Sistem DGX B300 melebihi performa puncak Sierra dalam inferensi FP4 (144 petaFLOPS vs 125 petaFLOPS).
Sistem DGX GB300 NVL72, capai 1.1 ExaFLOPS FP4 ( atau 1100 petaFLOPS diatas Sierra 125 petaFLOPS. DGX GB300 NVL72. 8.8 x lebih cepat dalam performa inferensi FP4.
Benchmarking Konsumsi daya antara NVIDIA Blackwell B300 & DGX B300 NV72 dengan IBM Sierra Supercomputer tahun 2018
Konsumsi Daya Puncak Sierra Supercomputer (2018) sekitar 11 megawatt (MW) atau 11.000 kilowatt (kW) untuk capai 125 petaFLOPS. 5 x lebih efisien dari pendahulunya Sequoia
Sistem DGX B300 terdiri dari 8 GPU Blackwell Ultra B300 konsumsi daya sekitar 14 kW mencakup GPU, CPU, RAM, penyimpanan, & komponen lainnya.
Sistem DGX GB300 NVL72 rack-scale gabungkan 72 Blackwell Ultra GPUs dan 36 Grace CPUs dirancang untuk capai performa exascale konsumsi daya sekitar 120 kW

Blackwell Everywhere: And the engine now powering this entire AI ecosystem is NVIDIA Blackwell, with Huang showing a slide explaining how NVIDIA offers “one architecture,” from cloud AI to enterprise AI, from personal AI to edge AI.
NVIDIA Product Category – DGX Spark Stations
DGX Spark available for different type of Architecture from Cloud AI, Enterprise AI, Personal AI to Edge AI. DGX Spark now in full production with partner like Dell, HP Enterprise, Asus MSI, Gigabyte, Lenovo will be shipped in a few week time (2025).
DGX Spark is designed for AI Native Developer, Student, Researcher, you don’t want to work in the Clouds and continuously getting the project prepared and then you have to scrubbing it, when you are done. You can have your own basic AI Clouds or Supercomputer on premise for your prototyping, next to you, and its always on and waiting. Its 1 Petaflops and 128 GB LPDDR5X memory.
In 2016 when NVIDIA delivered DGX1 an 1 Petaflops 128 GB HBM memory available from Dell, HPE, Asus, Gigabyte, MSI, Lenovo as your own personal DGX Supercomputer.
DGX 1 Station can run 1 trillion parameter AI Model Llama 70B(2016). These systems are AI Native specially build for this new generation of AI software. It does not have to be x86 compatible or run traditional IT software or Hypervisor or Windows. These computers are designed for the modern AI native application. Of course, this AI apps could be APIs that can be called upon by traditional and classical Application.
Now, DGX Station is a powerful system with up to 20 petaflops of performance powered from a wall socket. Huang said it has the capacity to run a 1 trillion parameter model, which is like having your “own personal DGX supercomputer.”
NVIDIA RTX PRO Server
Huang also announced a new line of enterprise servers for agentic AI, NVIDIA RTX PRO Servers, part of a new NVIDIA Enterprise AI Factory validated design, are now in volume production. Delivering universal acceleration for AI, design, engineering and business, RTX PRO Servers provide a foundation for NVIDIA partners to build and operate on-premises AI factories.

NVIDIA RTX Pro Server – Enterprise AI & Industrial AI Platform
RTX Pro Enterprise & Omniverse Server including x86 apps, Classical hypervisor, Kubernetes in those hypervisor manage your cluster and orchestrate your work load..This is the computer for Omniverse applications & Enterprise AI Agent, those AI agent could be only text or graphics.
New Blackwell RTX Pro 6000 motherboard is a switch network. CX8 is a new category of networking chips. In the CX8 you plug in several GPU card and communication between them & the networking bandwidth is 800GB/s and transceiver for networking interface to each GPU & between GPU on East West Traffic. The performance of an AI Factory and the throughput in token/sec.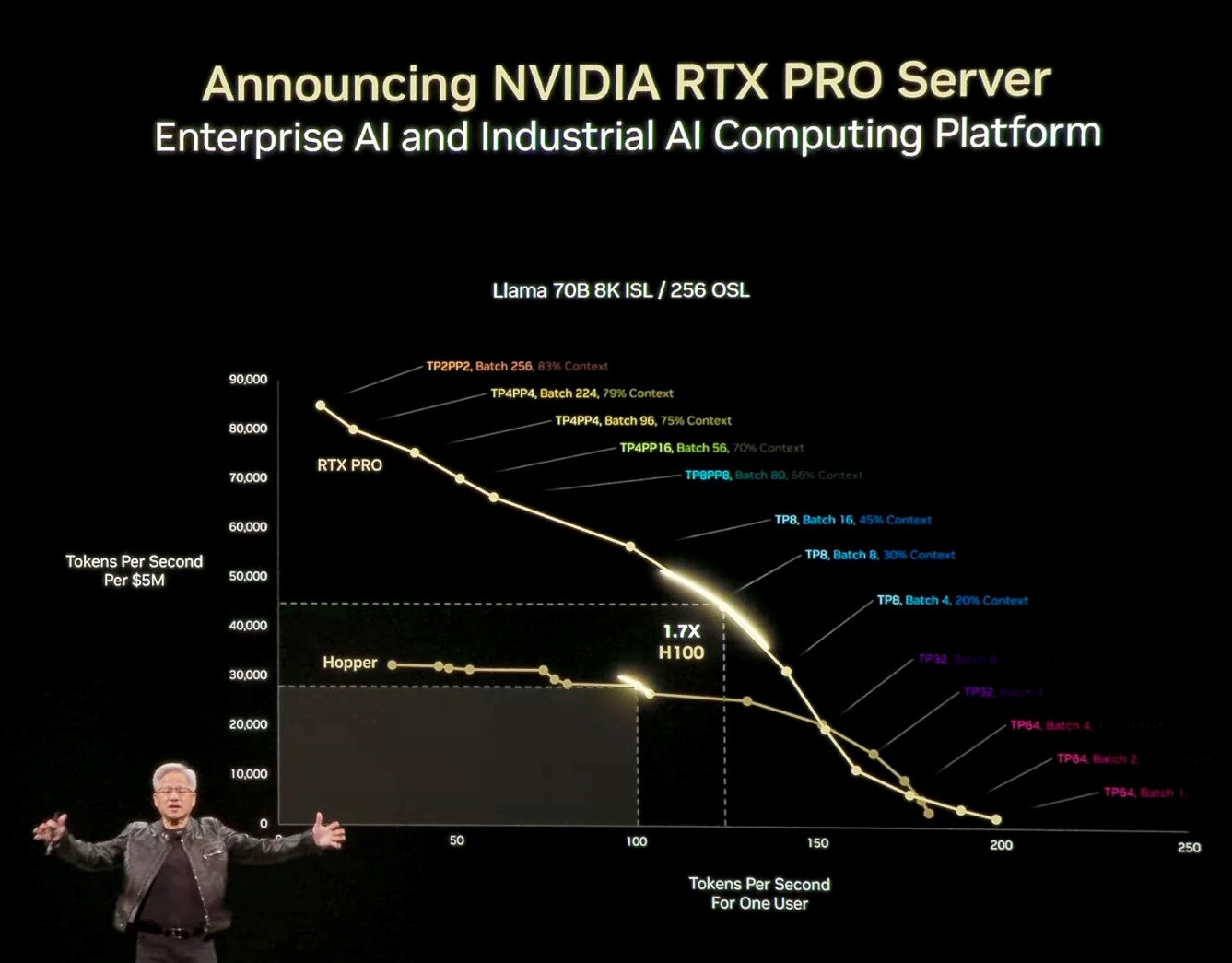
How the performance in AI Factory measure in Throughput Token per Sec which is the Y axis. The more output you produce, the more token you produce. However every AI model is not the same. Some AI model require much more reasoning, so you need high performance per user. AI Factory like high throughput or low latency. But it does not like to have both. So the challenge how we can have an OS that has high throughput, the Y axis, while having very low latency which is the Y axis. Interactivity, token per sec per sec per user
So this chart tell you something about the overall performance of the computer/ factory on RTX Pro.
The different color reflect on the different ways, you have to configure NVIDIA GPU to achieve the performance. Sometimes you need pipeline parallelism. Sometimes expert parallelism, some times batch or speculative decoding, sometimes you don’t.
And so all of those different types of algorithms have to be applied separately & differently depending on the workload and the pareto on the outside area. The overall area of that curve represent the capability of your factory. Hopper H100 ($225,000) used to be the most famous computer in the world.
And the Blackwell RTXPro Enterprise Server is 1.7 x Hopper performance. The HGX H100. This is Llama 70B. This is the Deepseek R1. Deep Seek R1 is 4x.
The reason is that Deepseek RI has been optimized & is genuinely a gift to the world AI industry. The amount of computer science breakthrough is significant. And it really open up a lot of great research in USA & around the world. Deepseek R1 has made great impact in how people think about AI and how about inference and how they think about reasoning AI
The Great contribution to the industry & the world. DeepSeek R1 the performance is 4x the state of the art H100. So if you ‘re building enterprise AI, we now have a great server
NVIDIA AI Data Platform
The compute AI Data platform is different than tradisional Data Platform, so the storage platform for modern AI Data Platform is different. To that end, Huang showcased the latest NVIDIA partners building intelligent storage infrastructure with NVIDIA RTX 6000 PRO Blackwell Server Edition GPUs and the NVIDIA AI Data Platform reference design.
The reason for the differences, is because humans traditional query structured data bases like SQL & Database Storage Server, but AI want to query unstructured data to get insight in the form of semantic & meaning.
So NVIDIA need to create a new type of storage platform called NVIDIA AI Data Platform, probably the idea is from Hadoop Ecosystems. On top of New type Storage system is a new query system, called NVIDIA IQ. The future storage is no longer a CPU on top a rack of storage, instead a GPU on top a rack of storage. Because you need the system to embedded & find a meaning in the unstructured data, the raw data, then you have to index, search and ranking the data.
So most storage in the future will have a GPU computing in front of it. It’s based on the NVIDIA AI model & put a lot of technology into post training of Open AI. Post train these AI Model with data that is completely transparent, safe & secure data to the user. The post trained model performance is realy incredible
Right now downloading open source reasoning model: The Llama neutron Reasoning is the world best & popular. Its 15 times faster with 15% better query result than equivalent model. The NVIDIA IQ are open source and we work with the storage industry to integrate these model into their storage stack.
Dell & Hitachi have great AI Platform leading storage vendors, & IBM AI Data Platform with Nvidia Nemo & NetApp also build AI Platform. You can building an AI Platform with a semantic query AI in front of it and Nvidia Nemo. Now you have Compute and Storage Infrastructure for Enterprise.
The next part is a new layer of software called AI Ops. Just as supply chain has their ops, HR has their ops. In the future IT has AI Ops. And they will curate data. They will fine tune the model/ evaluate, guardrail & secure the model. And we have the whole bunch library of model necessary to integrate into AI Ops ecosystems. We have great partner to do that, Crowdstrike also work with NVIDIA
You could see, this are AI operation creating, fine tuning & deploying model, ready for the Gen AI.














{kind=link}