


Jakarta, Komite.id – Masih banyak lagi yang akan datang, menggambarkan kekuatan kecerdasan buatan (AI) yang semakin berkembang dalam kemampuan bernalar dan memahami. “Hal ini membawa kita ke era AI agen—AI yang mampu memahami, berpikir, dan bertindak. Setelah itu muncul AI fisik, yaitu AI yang dapat memahami dunia nyata. Dan fase berikutnya, menurut Huang, adalah robotika umum.” ucap Jensen Huang
Kisah NVIDIA dimulai dari fase awal industri komputer. Perusahaan ini lahir sebagai produsen chip dengan visi menciptakan platform komputasi baru. Pada tahun 2006, NVIDIA memperkenalkan CUDA, yang merevolusi cara kerja komputer. Sepuluh tahun kemudian, pada 2016, pendekatan komputasi baru pun hadir—mendorong penemuan ulang di setiap lapisan tumpukan teknologi.
Segala hal mulai dari prosesor, perangkat lunak, hingga sistem harus didesain ulang. Maka, NVIDIA merancang sistem baru bernama NVIDIA GTX-1, namun pada saat itu belum banyak yang memahami ataupun tertarik. Karena itu, Jensen Huang memilih untuk mendukung sebuah organisasi nirlaba bernama OpenAI, yang kemudian menjadi pemicu revolusi AI global.
Berbeda dari pendekatan tradisional—yaitu menjalankan perangkat lunak pada prosesor di pusat data besar (hyperscale)—aplikasi AI generatif membutuhkan ribuan proses yang bekerja secara kolaboratif dan simultan. Sistem ini harus mampu melayani permintaan dari jutaan pengguna, dan pusat data pun harus dirancang dengan cara yang benar-benar berbeda.
NVIDIA menyadari adanya dua jenis jaringan utama. Jaringan utara-selatan, yang mengatur penyimpanan dan koneksi keluar, dan jaringan timur-barat, yang lebih krusial, karena memungkinkan komunikasi intensif antar komputer untuk menyelesaikan masalah bersama. Untuk menguasai jaringan timur-barat skala tinggi, NVIDIA mengakuisisi perusahaan spesialis jaringan bernama Mellanox pada tahun 2019 seharga $6,9 miliar.
Langkah ini mengubah konsep pusat data: bukan lagi kumpulan server, melainkan satu kesatuan unit komputasi. Di era baru ini, seluruh pusat data menjadi satu komputer raksasa yang menjalankan satu pekerjaan: menjawab permintaan AI generatif. Transformasi ini menandai NVIDIA sebagai pusat dari infrastruktur AI global.
Huang membandingkan revolusi ini dengan revolusi industri pertama, saat perusahaan seperti GE, Westinghouse, dan Siemens membangun infrastruktur listrik di seluruh dunia. Puluhan tahun kemudian, generasi kita mengalami revolusi kedua: infrastruktur informasi, yang awalnya sulit dipahami, namun kini dikenal sebagai Internet—suatu jaringan global yang menghubungkan segalanya.

Kini, dunia memasuki fase ketiga: infrastruktur kecerdasan (AI), yang dibangun di atas fondasi listrik dan Internet. Infrastruktur AI kini terintegrasi ke dalam setiap aspek kehidupan: setiap wilayah, industri, negara, bahkan perusahaan, semuanya membutuhkan AI.
AI bukan lagi sekadar teknologi, tetapi telah menjadi infrastruktur utama abad ini—setara dengan listrik dan Internet. Dan seperti revolusi sebelumnya yang membutuhkan pabrik-pabrik listrik atau pusat data Internet, revolusi AI membutuhkan Pabrik AI: pusat data khusus untuk AI. Itulah yang kini menjadi fokus utama NVIDIA: membangun Pabrik AI masa depan.
Pabrik AI yang dimaksud Jensen Huang bukanlah pusat data tradisional seperti di masa lalu. Pusat data konvensional dulunya hanya berfungsi untuk menyediakan informasi dan penyimpanan. Namun, Pabrik AI saat ini adalah pusat data generasi baru—Pusat Data AI (AI Data Center/DC)—yang memiliki nilai industri mencapai $1 triliun.
AI Data Center ini bekerja seperti pabrik digital: Anda mengalirkan energi ke dalamnya, dan alih-alih menghasilkan barang fisik, ia menghasilkan token—unit hasil kerja AI. Kini, perusahaan-perusahaan mulai berbicara tentang seberapa banyak token yang mereka hasilkan dalam kuartal terakhir, bulan lalu, bahkan jam terakhir, sebagaimana pabrik-pabrik biasa melaporkan volume produksi.
Inilah bukti bahwa Revolusi AI telah mengubah dunia secara mendasar. AI Data Center kini menjadi tulang punggung ekonomi digital baru, dan permintaan terhadap daya komputasi melonjak drastis.
Untuk memenuhi kebutuhan ini, Jensen Huang memaparkan inovasi terbaru NVIDIA: dari sistem Grace Blackwell NVL72, teknologi jaringan tercanggih, hingga instalasi pusat AI berskala besar yang tengah dibangun bersama mitra-mitra global seperti CoreWeave, Oracle, Microsoft, xAI, dan lainnya di seluruh dunia.
“Ini adalah investasi pabrik yang sangat besar. Dan alasan orang berinvestasi di pabrik ini sangat sederhana,” kata Huang sambil tersenyum.
“Semakin banyak Anda membeli, semakin banyak yang Anda hasilkan.”

Grace Blackwell NVL72: Mesin Pemikir Generasi Baru
Chip super Grace Blackwell merupakan terobosan besar. Chip ini dirancang bukan hanya untuk meningkatkan kapasitas, tetapi juga meningkatkan skala komputasi. Artinya, ia mampu mengubah satu komputer menjadi superkomputer raksasa.
Berbeda dengan peningkatan kapasitas (scaling out), yang berarti menambahkan banyak komputer dan menghubungkannya, peningkatan skala (scaling up) adalah tantangan teknis besar. Membangun satu komputer besar dengan kekuatan luar biasa menabrak batas fisika semikonduktor yang ada.
Namun, Grace Blackwell berhasil menembus batas-batas itu—menyelesaikan hampir semua hambatan yang sebelumnya dihadapi dunia chip. NVIDIA tidak bekerja sendiri; banyak mitra di Taiwan seperti TSMC, Foxconn, Gigabyte, dan MediaTek turut membantu merancang dan membangun infrastruktur AI, termasuk sistem berbasis Grace Blackwell.
Jensen Huang dengan bangga menyatakan bahwa produksi massal Grace Blackwell sedang berlangsung penuh, meskipun sangat menantang. Sistem Blackwell berbasis HGX sudah mulai diproduksi sejak akhir tahun 2024 dan telah tersedia secara komersial sejak Februari 2025.
Kini, Grace Blackwell NVL72—yang dijuluki “Mesin Pemikir”—telah resmi diluncurkan dan telah hadir di berbagai platform cloud. Sistem ini sudah digunakan oleh banyak CSP (Cloud Service Provider) dan mulai terlihat digunakan secara luas di berbagai sektor industri dan teknologi.
Pengguna dan pengembang di seluruh dunia bahkan telah mulai menciuit dan membagikan bahwa Grace Blackwell benar-benar telah memasuki tahap produksi penuh.
Pada kuartal ketiga tahun ini, seperti yang telah saya janjikan, kami akan kembali meningkatkan performa platform kami—sejalan dengan ritme peningkatan tahunan yang konsisten. Tahun ini, peningkatan tersebut diwujudkan melalui peluncuran Grace Blackwell GB300.
Meskipun menggunakan arsitektur dasar, jejak fisik, sistem kelistrikan, dan mekanik yang sama dengan generasi sebelumnya, sistem ini mengalami pembaruan signifikan melalui penyematan chip Blackwell terbaru. Hasilnya:
Kinerja inferensi meningkat 1,5 kali dibandingkan pendahulunya (B200),
Kapasitas HBM (High Bandwidth Memory) untuk GPU dan superkomputer juga meningkat 1,5 kali,
Sementara bandwidth jaringan meningkat dua kali lipat, meningkatkan efisiensi komunikasi data skala besar antar node.

Dari Generasi B200 ke B300
Grace Blackwell memulai dengan simpul komputasi baru yang secara visual menyerupai generasi sebelumnya, B200. Namun, versi B300 kini sepenuhnya mengandalkan sistem pendinginan cair (liquid cooling) dan kompatibel untuk diintegrasikan ke dalam sistem yang sama.
B300 memiliki:
- Kinerja inferensi 1,5 kali lebih tinggidibanding B200,
- Kinerja pelatihanyang relatif setara.
Yang luar biasa, satu node Blackwell B300 memiliki performa komputasi hingga 40 petaFLOPS—setara dengan performa superkomputer Sierra milik IBM pada tahun 2018, yang saat itu menggunakan 18.000 GPU NVIDIA Tesla V100.
Artinya, satu simpul B300 mampu menggantikan seluruh superkomputer besar. Ini mencerminkan lompatan performa sebesar 4000× hanya dalam 6 tahun—mewakili“versi ekstrem dari Hukum Moore.”
Perbandingan Kinerja Grace Blackwell & Superkomputer Sierra
IBM Sierra (2018):
l Kinerja Puncak: 125 petaFLOPS
- Kinerja Aktual: 120,9 petaFLOPS
- Arsitektur: CPU IBM Power9 + GPU NVIDIA Tesla V100
- Jumlah GPU: 18.688 unit
- Tujuan: Simulasi senjata nuklir di Lawrence Livermore National Laboratory
NVIDIA Grace Blackwell DGX B300/GB300 (2025):
Kinerja Inferensi:
- 144 petaFLOPS (FP4)
- 72 petaFLOPS (FP8, untuk pelatihan)
- Kinerja Pelatihan Padat: 15 petaFLOPS (FP4 dense)
- Teknologi Pendinginan: 100% liquid cooling
- Ukuran Fisik: Setara satu node, kompatibel dengan sistem generasi sebelumnya
Perjalanan NVIDIA dalam mengembangkan sistem Grace Blackwell GB300 menunjukkan bagaimana AI dan komputasi telah berkembang pesat. Seiring meningkatnya tuntutan terhadap AI generatif dan beban kerja HPC (high-performance computing), node-node komputasi cerdas seperti GB300 kini menjadi tulang punggung infrastruktur AI global.
“Kami telah meningkatkan skala komputasi hingga sejuta kali lipat setiap 10 tahun, dan kami masih berada di jalur yang sama. Tapi ini bukan hanya tentang membuat chip tercepat—melainkan membangun seluruh sistem,” ujar Jensen Huang.

NVIDIA DGX GB300 NVL72: Superkomputer AI Generasi Baru
Sistem DGX GB300 NVL72 menggunakan 72 GPU Blackwell Ultra dan 36 CPU Grace, mampu mencapai performa hingga 1,1 exaFLOPS (FP4) untuk inferensi dan 360 petaFLOPS (FP8) untuk pelatihan model AI. Dengan kemampuan ini, NVIDIA secara signifikan melampaui kinerja superkomputer generasi sebelumnya.
Sebagai perbandingan, IBM Sierra (2018) memiliki performa puncak sebesar 125 petaFLOPS (FP4). Artinya, DGX GB300 NVL72 8,8 kali lebih cepat dalam inferensi dibanding Sierra.
Efisiensi Energi yang Mengungguli Generasi Sebelumnya
- IBM Sierra (2018):Konsumsi daya sekitar 11 megawatt (MW) untuk mencapai 125 petaFLOPS.
- DGX B300 (8 GPU Blackwell Ultra):Konsumsi daya sekitar 14 kW untuk sistem lengkap.
- DGX GB300 NVL72 (rak penuh):Konsumsi daya sekitar 120 kW, jauh lebih efisien untuk skala performa exascale.
Blackwell di Mana-mana: Satu Arsitektur untuk Semua AI
Huang menekankan bahwa NVIDIA Blackwell menjadi mesin penggerak seluruh ekosistem AI — dari cloud AI, enterprise AI, personal AI, hingga edge AI — dalam satu arsitektur terpadu.
DGX Spark: Superkomputer AI Pribadi
Produk terbaru seperti DGX Spark kini tersedia untuk berbagai segmen, termasuk mahasiswa, pengembang, dan peneliti. DGX Spark dilengkapi dengan:
- Memori LPDDR5X 128 GB
- Performa hingga 1 petaFLOPS
DGX Spark tersedia dari mitra seperti Dell, HPE, ASUS, Gigabyte, MSI, dan Lenovo. Sistem ini memungkinkan pengguna memiliki “cloud pribadi” untuk pengembangan AI tanpa harus mengandalkan layanan cloud publik.
DGX 1 Station: Evolusi Superkomputer AI Pribadi
Sejak tahun 2016, DGX 1 Station mampu menjalankan model AI besar seperti Llama 70B (dengan 1 triliun parameter). Dirancang sebagai sistem AI-native, perangkat ini tidak perlu mendukung arsitektur x86, Windows, atau hypervisor tradisional. Kini, versi terbarunya memiliki performa hingga 20 petaFLOPS, langsung dari stopkontak rumah.

NVIDIA RTX PRO Server: Pabrik AI di Dalam Perusahaan
NVIDIA juga memperkenalkan server RTX PRO, bagian dari desain validasi Enterprise AI Factory:
- Menyediakan akselerasi universal untuk AI, desain, dan rekayasa
- Mendukung arsitektur klasik: x86, hypervisor, Kubernetes
- Dioptimalkan untuk aplikasi seperti Omniversedan Enterprise AI Agent
Arsitektur Jaringan Blackwell RTX Pro 6000
Menggunakan chip jaringan CX8, sistem ini mendukung komunikasi antarkartu GPU dengan bandwidth hingga 800 GB/s — penting untuk lalu lintas data East-West antar-GPU.
AI Factory dan Ukuran Kinerja: Token per Detik
Kinerja diukur dalam throughput token per detik:
- Model dengan kebutuhan penalaran tinggi memerlukan performa per pengguna yang besar.
- Tantangan utama adalah menggabungkan throughput tinggi(jumlah token/detik) dan latensi rendah secara bersamaan.
Optimasi GPU: Sesuai Jenis Beban Kerja
Warna dalam grafik performa menggambarkan strategi optimasi GPU:
- Paralelisme jalur pipa
- Paralelisme ahli
- Decoding batch
- Inferensi spekulatif
Semua strategi ini diterapkan tergantung pada profil beban kerja AI Anda.
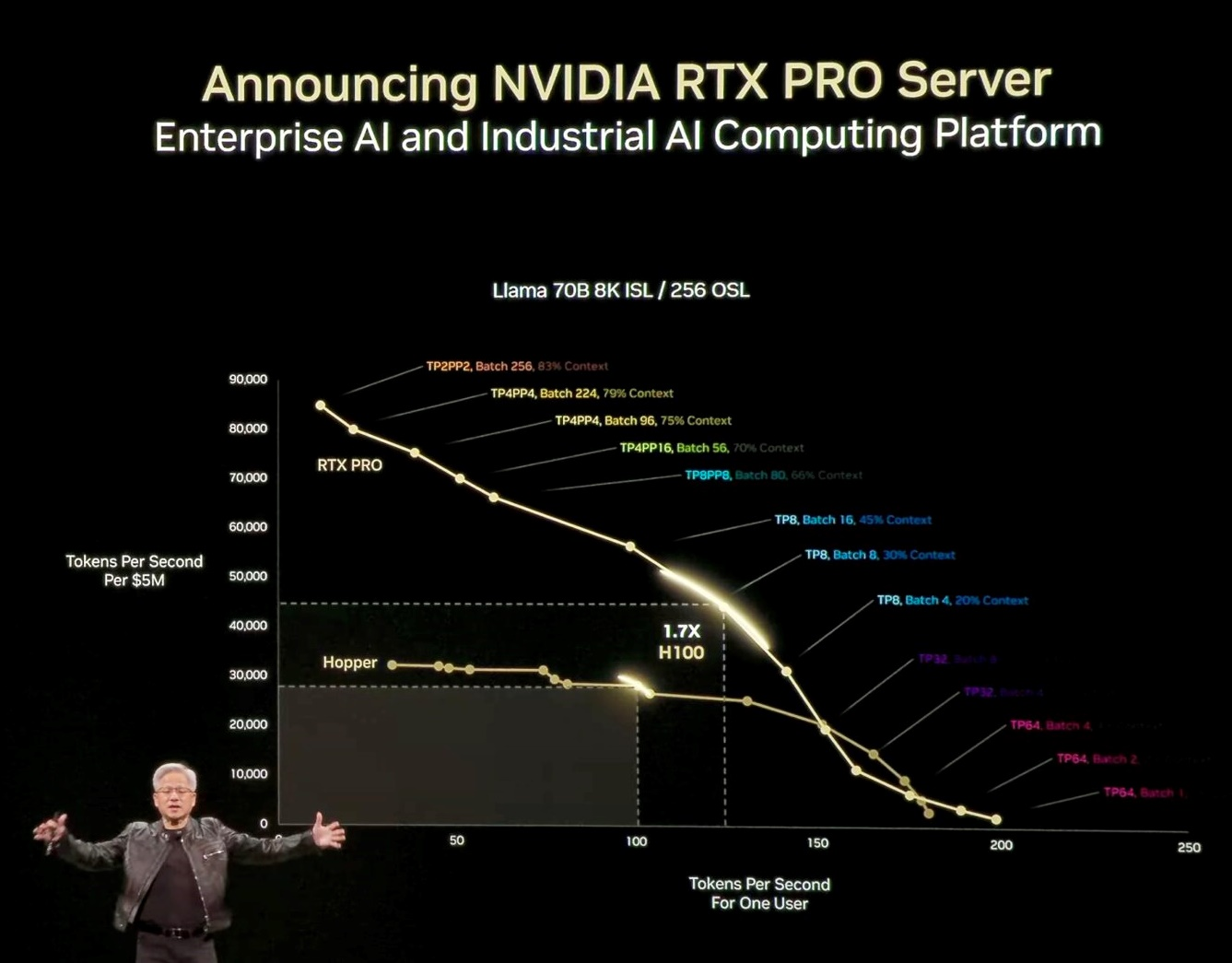
DeepSeek R1 dan Lompatan Kinerja AI
Model DeepSeek R1 menunjukkan performa yang 4 kali lebih tinggi dari H100, dengan efisiensi dan hasil penalaran yang sangat unggul. Optimalisasi model ini membuka banyak terobosan ilmiah, dan dianggap sebagai kontribusi besar untuk industri AI global.
Dengan NVIDIA RTX Pro Enterprise Server, yang memiliki performa 1,7x dari HGX H100, industri kini memiliki fondasi kuat untuk membangun dan menjalankan AI perusahaan secara efisien dan skalabel.
NVIDIA AI Data Platform: Evolusi Penyimpanan Menuju Era AI Generatif
Platform data untuk komputasi AI sangat berbeda dengan platform data tradisional, sehingga infrastruktur penyimpanannya pun memerlukan pendekatan baru. Dalam keynote COMPUTEX 2025, CEO NVIDIA Jensen Huang memperkenalkan mitra terbaru yang bekerja sama membangun infrastruktur penyimpanan cerdas, memanfaatkan GPU NVIDIA RTX 6000 PRO Blackwell Server Edition dan desain referensi dari NVIDIA AI Data Platform.
Mengapa Platform Data AI Berbeda?
Secara tradisional, manusia mengakses basis data terstruktur seperti SQL melalui server penyimpanan berbasis CPU. Namun, AI bekerja secara berbeda. AI membutuhkan akses terhadap data tidak terstruktur—seperti teks bebas, gambar, audio, dan video—untuk menemukan wawasan semantik dan makna yang mendalam.
Karena itu, NVIDIA menciptakan pendekatan baru dalam arsitektur penyimpanan: GPU di atas rak penyimpanan, bukan CPU. GPU digunakan untuk melakukan embedding, memahami konteks, serta melakukan pencarian dan pemeringkatan data tidak terstruktur secara real time.
Desain ini mengingatkan pada filosofi ekosistem Hadoop di masa lalu, namun kini dikembangkan dengan akselerasi AI generatif dan GPU.

NVIDIA IQ: Lapisan Permintaan Cerdas untuk Data Tidak Terstruktur
Di atas sistem penyimpanan generasi baru ini, NVIDIA memperkenalkan NVIDIA IQ — sistem open-source query engine berbasis semantik yang dirancang khusus untuk AI. IQ memungkinkan sistem untuk menanyakan data tidak terstruktur seperti layaknya manusia mencari makna, bukan hanya kata kunci.
Keunggulan NVIDIA IQ:
l Menggunakan model reasoning seperti Llama Neutron, salah satu model open-source paling unggul saat ini.
- Llama Neutron mampu bekerja:
- 15x lebih cepatdibandingkan model sekelasnya
- Memberikan akurasi kueri 15% lebih tinggi
- NVIDIA IQ sedang diintegrasikan oleh berbagai vendor penyimpanan terkemuka, termasuk:
- Dell Technologies
- Hitachi
- IBMmelalui AI Data Platform & NVIDIA NeMo
- NetApp
Penyimpanan yang Terintegrasi dengan AI
Penyimpanan masa depan akan menjadi platform yang aktif dan cerdas, bukan sekadar tempat menyimpan data, melainkan tempat memahami, mengindeks, dan mengekstraksi makna secara langsung. Dengan arsitektur baru ini, NVIDIA tidak hanya menyediakan infrastruktur komputasi melalui GPU Blackwell, tetapi juga infrastruktur penyimpanan untuk seluruh siklus hidup AI—dari pelatihan hingga inferensi dan penalaran.
AI Ops: Operasi AI sebagai Lapisan Baru TI Modern
Tahap selanjutnya adalah menghadirkan AI Ops, sebuah lapisan perangkat lunak operasional untuk mendukung siklus kerja AI, sebagaimana supply chain memiliki ops, dan HR memiliki HR ops.
Fungsi AI Ops:
- Mengkurasi dan membersihkan data
- Menyempurnakan dan mengevaluasi model
- Mengamankan dan memelihara model dalam produksi
- Menyediakan pustaka model siap pakai yang dapat diintegrasikan ke dalam ekosistem Gen AI
NVIDIA bekerja sama dengan mitra industri, seperti Crowdstrike, untuk memastikan bahwa AI Ops berjalan dengan standar keamanan, transparansi, dan keandalan tinggi, sekaligus siap menangani skala perusahaan.
Dengan NVIDIA AI Data Platform, NVIDIA IQ, dan AI Ops, NVIDIA membangun fondasi teknologi penuh untuk era AI generatif—mencakup komputasi, penyimpanan, pengelolaan, hingga eksekusi. Ini adalah lompatan arsitektur besar untuk perusahaan yang ingin bergerak dari TI konvensional menuju AI-native infrastructure.





")









{kind=link}